



ほんのちょっと未来の広告を考えてみる
ちょっと先に見えている広告の未来。そのための研究を行っているマイクロアド未来広告研究所がお送りする、広告テクノロジーとデータ利用の話。(全6回)

第3回:データはマーケティングを変えるのか?
昨今、日本に大旋風を巻き起こしているものといえば、「ももいろクローバーZ」と「ビッグデータ」ですね。(ですよね?)
両者とも流行語としては十分に行き渡った感がありますが、単なる流行として終わるのか、ホンモノと評価されて定着するのか、中身を試されるフェイズに入っているのではと思います。
ももクロについては専門ではないので、今回は広告屋の立場から、“ビッグデータ”は広告/マーケティングの本質に影響を与えるのか、それともただのバズワードなのかを考えたいと思います。
<マーケティングではデータをどう使っている?>
もともとマーケティングではデータを多く利用します。人口統計、マクロ経済動向、消費動向、業界動向、技術動向、競合調査、消費者調査、流通調査、満足度調査、ブランドリサーチ、メディア動向、広告シェア、広告効果調査、POSデータなど、これでもほんの一部に過ぎません。
これらのデータ(“ビッグ”じゃなくても)をマーケッターはどのように活用しているか、整理してみましょう。私の経験では、大きく以下の4つがあると思います。
1)予測
過去の実績データをもとに、将来を予測、もしくは条件を変えた場合に結果がどうなるかを予測すること。プロモーション予算・人員配分・生産調整・配荷・価格などにフィードバックされます。
2)結果の評価
マーケティング施策の結果を“定量的に”評価すること。過去データから得られたノーム値や目標値、マイルストーンとの数値比較。PDCAの“C”ですね。A/Bテストもこちらです。1) と同様の項目についてフィードバックされますが、分析・評価の時間が短ければ素早い改善につながります。
3)事象の理解
統計分析、データマイニング、クロス集計などを用いて量的な情報を質的な情報に変換し、現在起こっていることや周辺事象を把握、さらにその原因、理由などを深掘っていくこと。「データからインサイトを得る」などと表現されるのもこの領域です。業務知識やその他幅広い知識、またセンスが必要になります。商品企画の際やマーケティングコンセプトを練る時、ターゲティングなど上流工程で利用されます。また、パッケージデザインや商品スペック、広告メッセージや広告表現などの開発や修正にも利用されます。
4)説得
周囲を説得するための言語ツールとしてのデータ。社内でコンセンサスを得ようとするときはもちろん、マーケティングコミュニケーションにおいて生活者もしくは関係者を納得させるためにデータを使うことがあります。
ここに“ビッグ”なデータがやってくると何が変わるのでしょうか。質的な転換はあるのでしょうか。
それとも「ちょっとだけ精度が良くなる」程度の話なのでしょうか。
<ビッグデータの特徴>
まずはビッグデータの特徴から見てみましょう。
Volume: データ量が多い
Variety: 複数のソースからのいろいろな種類のデータ、非構造化データ(音声、画像、テキスト、センサーデータなど)
Velocity: リアルタイムでのデータ取得、処理、分析
IBMでは、もう一つ
Veracity: 信頼性
を足して“4Vs”だと定義していますが、データが大きいことによる信頼度のアップという側面が強いため、個人的には3つでいいかなと思っています。誤解していたらすみません。
これらの特徴がマーケティングに何をもたらすのか、ひとつひとつ見ていきましょう。
<Volume>
ちょっと大きめのデータを手に入れたくらいでは、予測の精度がほんのちょっと改善される程度です。場合によっては、データをいくら大きくしても、精度の改善にはほとんど意味をなさないこともあります。
コインを投げてオモテが出る確率は1/2(0.5)ですね。(インチキは無しとします) しかし、5回投げてすべてがオモテだったり、10回投げてすべてオモテになることもまれにあることもありますよね。
では、実験してみましょう。20回ほど私の子供に投げさせてみましたが飽きてしまったようなので、コンピュータでシミュレーションさせました。コンピュータで0〜1までの乱数を発生させ、0.5より大きければオモテと判断します。それを10回、30回、50回、100回、1,000回、1万回、100万回、1,000万回のセットをそれぞれ100回ずつトライしました。
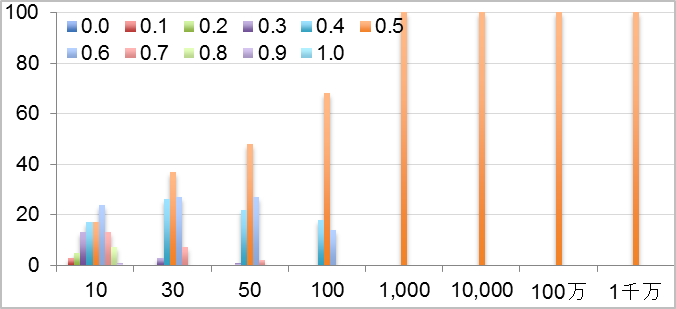
しかし出現確率が少ない場合、データ量の大きさが威力を発揮します。オンラインマーケティングで使われるコンバージョン率は一般的に0.1%、0.01%といった低い確率になることが多いです。確率が低いとそれが偶然または誤差なのか、意味のあるものなのかを判断するのが非常に困難です。例えば、男性のコンバージョン率が0.01%で、女性のそれが0.02%だった場合、男女の購買傾向の差に意味があるのか、たまたまぶれてしまっただけなのか、統計的に検証するためには1,500万ほどのサンプルが必要になります。
このように、出現率が少ない事象が「意味の無い誤差」なのか、「意味ある事象」なのかが、データ量が多ければ評価できます。そしてその少ない事象に対して「予測」をすることも可能になります。データ量が少ないときには誤差として「なかったこと」にされていた事象が、大量データによって「意味があるもの」として再発見されることもあるでしょう。
データ量が多ければ、以下のようにより細かい区分が可能になります。
Aさん スポーツカー+ヨーロッパブランドファッション
Bさん RV車+アウトドアファッション
Cさん ミニバン+カジュアルファッション
といったように、少し深堀できて複数のカテゴリにまたがった途端、3人それぞれの異なったライフスタイルが見えてきました。この連休、彼らは全然別の過ごし方をしたことが想像されますよね? もし旅行にいくなら、3人とも全然違うところにいきそうですね。もし同じ予算で家を買うとしても、3人の条件の優先順位はだいぶ違いそうですね。ある項目の理解の深度が深くなるだけでなく、それが重なることで、質の違った理解ができることがお分かりいただけたと思います。
<Variety>
Varietyには、大きく2つの意味があります。“複数ソースのデータを合体させる”ことと、“データ化しにくかったもののデータ化”です。
もう一つの、“データ化しにくかったもののデータ化”について、もっとも分かりやすいのはテキストマイニングの進化です。テキストマイニングの考え方はそれほど新しい物ではないのですが、内部ではめちゃくちゃ激しい計算が必要な分野の一つで、コンピューターの性能アップに伴い進化をしてきた領域です。音声化や画像化についても同様に進化してきています。
弊社の例で恐縮ですが、昨年、顔認証で性年代を判定し、それに応じて広告を出し分ける屋外広告の実験を行いました。広告を出し分ける機能は現在、実稼働しているシステムなのですが、顔認証モジュールから性年代の数値データを渡されるだけで、これまでとは違ったコミュニケーションの可能性を示しています。

ad:tech tokyo 2012に参考出展された顔認証ターゲティング広告機能付き自動販売機
ほんの15年程前、アンケートと言えば郵送での調査が主流でした。調査票を作ったら、それを印刷して封筒につめて、郵送して、回答が返送されてきて、その回答を手で入力して、集計して、とここまでで、どんなに早くても1ヶ月、大きな調査になると3ヶ月から半年以上かかるものもありました。ネットアンケートなら、調査票を作成してから回答の集計まで、早ければ半日もかからず行うことも可能です。これによりキャンペーン途中の軌道修正も可能になりました。場合によってはアンケートをやらなくても、直接反応を計測し、よいものを自動で選ぶという機能も利用できます。複数のバナー素材を用意して、クリック率が良いものを多く掲出するという方法はオンライン広告の世界では既に標準の手法でしょう。
以上、ビッグデータの特徴といわれる3つの側面から、マーケティングへの影響を考えてみました。ビッグデータによって、量的な変化よりも質的な変化が起こりそうだというのが私の印象です。ということは、いままでとは違う要素をプランニングに取り入れることができるため、これまで以上の自由度をもって、よりクリエイティブなマーケティングができるのでは、と期待しています。